<![CDATA[mind.dump()]]>2014-01-12T14:10:23+01:00http://blog.mymind.fr/Octopress<![CDATA[From Dotclear to Octopress]]>2013-12-29T22:07:24+01:00http://blog.mymind.fr/blog/2013/12/29/from-dotclear-to-octopressAfter more than four years of inactivity on my personal blog
(I’ve been busy blogging professionally
in the meantime), I’ve decided to migrate my old blog to
Octopress.
Several reasons for this. The first one is mostly that I don’t believe
Dotclear has a future anymore. At the time I chose
Dotclear over Wordpress, it was in very active development, going from 1.x
to 2.x with regular release and a very active community: it was a
promising software that could have fought side by side with wordpress.
Morevoer, it was a french software.
However, Dotclear is probably to much of a carbon copy of wordpress: same
technology (PHP), same admin architecture, … to make the difference.
Wordpress is backed by a dedicated compagny, and Dotclear which is made as a
hobby project just can’t catch up. As a consequence, there is no technical
reason to use dotclear over wordpress anymore: the later has a much more
active development pace, a wide ecosystem and a very active community…
Dotclear has been completely forgotten: only its own community care about
it. Tools such as Disqus don’t provide any integrated solution for dotclear,
leaving users to hack the code of their theme if they wish to integrate
that kind of service. Even tools that aims at providing migration utility
to other blogging platform don’t list Dotclear as a source platform.
The second reason is that I find it completely overkill to run some PHP
to serve a near-static content. My blog has not been update for 4 years, but
every time someone reads a page, it goes through some PHP. PHP may be (have
been) great for dynamic sites, but not for delivering content: it consumes
resources and may contain security hole. The sole dynamic part of the site
that is user-facing is the comment system… however nowadays services like
Disqus, Google or Facebook can be integrated in your site for this in just
a few lines of HTML/javascript (and by selling your soul to the devil):
you may have an interactive site with only static pages.
So, its done, my site has been migrated to a new static platform and is
hosted by github (which wasn’t mandatory but frees me from a bit of system
administration). I couldn’t find any packaged tool to perform the migration
so I wrote one small script by
myself. If the script is of interest for you here is how to proceed:
export the database and the media library of your blog from Dotclear maintenance
page
unpack the media library in the source/assets directory of Octopress
run the Python script on the database export (which should be named
python dotclear-octopress.py <date>-<blogname>-<backup>.txt (the scripts
runs in Python and requires pip install phpserialize)
the script should have generated a new directory that contains a series of
.csv file and a subdirectory called _posts that contains the markdown
pages for your old blog posts.
copy the content of _posts to source/_posts of Octopress.
At this point, the result is not perfect (but I’m sure the script can be improved),
you’ll still have to go through your posts and check that they were properly
markdownified (Dotclear source text is in a Dotclear-specific wiki syntax,
the script tries to do the conversion, but it is not 100% accurate and will
miss some corner cases).
The script also dump a file rss.xml that contains the extended RSS format that
can be used to import discussions on Disqus.
]]><![CDATA[Yet Another Policy Daemon for Postfix]]>2009-04-07T00:04:00+02:00http://blog.mymind.fr/blog/2009/04/07/yet-another-policy-daemon-for-postfix2MadCoder announced it months ago, he has been working on the pfixtools. The second tool of the postfix-related toolsuite is named postlicyd.
postlicyd is a versatile policy daemon written in C. It does greylisting (far faster than postgrey), it performs R(H)BL access (both locally directly from rbldns zone files and remotely by using DNS), … So, it can be used as a replacement for whitelister and postgrey with a significant improvement of the performances.
On the same server (with the same email trafic), postlicyd is more than 20 times faster than postgrey:
Process load: postgrey ~20% CPU, postlicyd less than 1% CPU
Data base cleanup for 1M entries: postgrey 20 minutes, postlicyd 40 seconds
Moreover, it is aware of the ‘session’ feature of the POLICY protocol. Thus, you can write complex configurations and define policies that do not depend on a single SMTP command (like RCPT) but on the whole SMTP transaction…
]]><![CDATA[Polytechnique.org Lance Son Blog]]>2008-06-04T01:33:00+02:00http://blog.mymind.fr/blog/2008/06/04/polytechniqueorg-lance-son-blogVoilà… cela fait assez longtemps que nous recevons des demandes d’utilisateurs pour la mise en place de blog via Polytechnique.org. Afin de préparer la mise en place de ce service, Polytechnique.org lance son blog. Cela permettra à la fois :
de tester l’outil d’intégration de l’authentification de Polytechnique.org dans Dotclear.
d’offrir une nouvelle plateforme souple et conviviale pour informer nos utilisateurs.
Je ne vais pas m’étendre davantage vu que ce ne serait que recopier le post d’Aymeric
]]><![CDATA[Vieux Trucs]]>2008-05-19T00:50:00+02:00http://blog.mymind.fr/blog/2008/05/19/vieux-trucsUn peu de nostalgie. Je suis retombé sur de vieux programmes que j’avais fait pour ma calculatrice (TI-92) quand j’étais en 1ère/Terminale. A mon époque (pas si lointaine… j’ai passé mon bac en 2001), ces outils couvraient le programme de Terminal S (spécialité maths) avec :
En analyse et algèbre :
tableaux de signe et de variation (avec détection de la périodicité des fonctions en cas de besoin)
équation différentielles (de Terminal, donc y' = a.y + w ou y" + w<sup>2</sup>.y = 0)
Le tout avec une interface permettant de passer d’un programme à l’autre simplement. Histoire que tout ceci ne se perde pas, je les met à disposition (ils sont également trouvables sur diverses banques de programmes pour TI) :
Evidemment, ces programmes ne dispensent pas d’apprendre le cours pour passer le Bac.
]]><![CDATA[Encodage Et Terminal]]>2008-03-02T12:57:00+01:00http://blog.mymind.fr/blog/2008/03/02/encodage-et-terminalBeaucoup de personnes avec qui je discute sur IRC ont des problèmes avec l’encodage de leur terminal, de leur shell, de leur irssi, ou de tout autre logiciel en “ligne de commande”. Comme j’en ai un peu marre d’expliquer la même chose toutes les semaines, voici une petite mise au point sur les réglages à faire pour travailler efficacement en ligne de commande.
Introduction
Le point le plus important à mémoriser est que pour avoir une console avec un encodage spécifique il faut que plusieurs couches de logiciels utilisent le même encodage. Prenons le cas simple où nous avons un shell dans un terminal.
Pour l’entrée de l’utilisateur, c’est la même chose. Si mon terminal est en latin1 et mon shell en utf8, si j’entre un “é” dans mon terminal, celui-ci sera passé à mon terminal comme un seul octet (de valeur 0xE9). Or mon shell attend de l’utf8 et lorsqu’il reçoit un 0xE9, il considère que je viens d’entrer un octet d’un caractère multi-octets… les prochains caractères que j’entrerais seront donc ajoutés à mon 0xE9 jusqu’à ce que mon shell considère que j’ai entré un caractère… assez embêtant.
Il faut donc faire extrêmement attention à choisir un encodage unique compatible avec son shell et son terminal (et les logiciels qu’on compte utiliser).
Terminal
Le réglage du terminal dépend exclusivement du logiciel en question. Certains terminaux permettent de choisir son encodage, d’autres non. Cela peut donc être un bon critère pour choisir son logiciel. Pour utiliser l’UTF-8, vous pouvez prendre Konsole, urxvt, le Terminal de Mac OS X…
Shell
Le réglage du shell se fait par des variables d’environnement qu’on appelle couramment les “locales”. Le réglage courant est accessible en tapant “locale” dans le shell. Un certain nombre de variables sont concernées :
gestion de la langue du shell (et des programmes liés)
gestion des formats (dates, monnaies, virgules…)
LC_ALL est un “fallback” (l’encodage par défaut si aucun autre n’a été défini pour une variable donnée).
Chaque variable est de la forme xx_YY.ZZ. xx_YY défini la zone géographique et la langue (fr_FR pour le français, en_US pour l’anglais-US). ZZ défini l’encodage. Il est important que toutes les variables utilisent le même encodage (mais elles peuvent avoir des langues différentes). Pour faire de l’UTF-8 pur, un bon choix est d’exporter LC_ALL=“en_US.UTF-8” dans la configuration du shell (ou fr_FR.UTF-8 pour ceux qui veulent un shell en français).
Il faut par contre faire attention, l’UTF-8 n’est pas supporté par tous les shells (à partir de 4.3 pour zsh par exemple).
Irssi
Pour irssi, il y a un point supplémentaire à prendre en compte : l’encodage du réseau. Ainsi si j’ai un channel en latin1 à afficher en utf8 (et sur lequel je veux poster). Il faut donc que irssi fasse de transcodage à la volée… et bien sûr il faut lui dire ce qu’il faut faire.
Tout d’abord il faut lui indiquer l’encodage du terminal. Pour ceci il y a la variable term_charset :
Ensuite, il faut indiquer pour chaque réseau (ou channel) l’encodage du réseau. Ce n’est en fait nécessaire que si l’encodage est différent de celui du terminal, mais ça ne coûte rien de le spécifier pour chaque réseau. Ainsi je suis sur RezoSup (qui est en latin1) et sur FreeNode (qui est en utf8), il me suffit d’ajouter :
Les entrées “FreeNode” et “Rezosup” doivent reprendre le nom du chatnet donné dans la section “servers” de la configuration. Pour spécifier l’encodage spécifique à un channel, il suffit de mettre "Chatnet/#channel" = "encoding";
]]><![CDATA[Afficher Des Discussions]]>2007-11-01T18:24:00+01:00http://blog.mymind.fr/blog/2007/11/01/afficher-des-discussionsLorsqu’un logiciel a pour vocation d’afficher des discussions, on attend de sa part qu’il nous permette de voir simplement qui répond à qui, dans quel contexte… Ce n’est pas toujours ce qui est le mieux fait. Par exemple, les programmes de fora en ligne à la mode (phpBB par exemple) affiche les discussion comme une succession de rectangles juxtaposés et seul le contenu du message permet de voir qu’il en cite un autre. D’autres logiciels comme Mail.app ont ce défaut et parfois la fâcheuse manie de ne pas vouloir corriger ce problème.
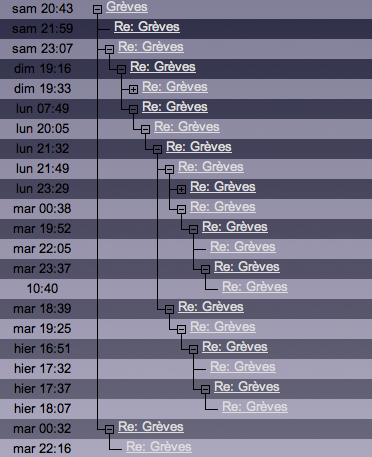
L’affichage de l’arborescence dans Banana est une des fonctionnalités clés… et elle va beaucoup changer dans la prochaine version.
Une ligne par entrée
La solution habituelle pour afficher l’arborescence est d’utiliser un message par ligne de telle, des + ou – pour ouvrir ou fermer les noeuds. C’est la solution actuelle de banana.
Avec cette solution, on perd très rapidement en lisibilité : dès que la discussion dépasse une vingtaine de messages, l’arborescence devient très haute et plus ça va, plus le titre dérive vers la droite rendant parfois le lien inaccessible. Lorsqu’il y a un troll, il est de fait très courant que certains nouveaux messages se trouvent perdus plusieurs pages en arrière dans l’arborescence, ou que sur certains navigateurs, il soit difficile d’y accéder. De plus l’interface se trouve souvent surchargée, à la limite de la lisibilité : c’est dur de faire tenir un maximum d’informations en un minimum de place en gardant la lisibilité de l’ensemble.
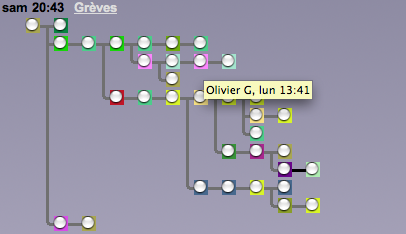
Une solution plus visuelle
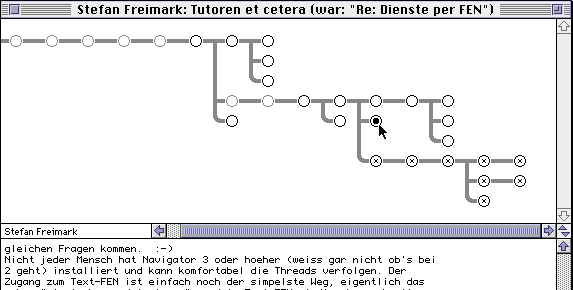
Je ne sais pas combien de personnes connaissent MacSoup. Il s’agit d’un petit client NNTP pour MacOS, qui en soit n’a pas beaucoup d’intérêt (il est payant et est relativement limité). Le principal atout de MacSoup est son interface de visualisation des threads (les utilisateurs diront qu’il y a bien plus que l’interface graphique, mais également l’interface clavier etc…). On trouve sur internet quelques captures d’écran en cherchant dans les moteurs de recherche d’image :
Cette interface est compacte, visuelle et permet d’accéder rapidement à n’importe quel message du thread. Pour la prochaine version de Banana, je me suis fortement inspiré de cette interface pour réécrire de 0 l’affichage de l’arborescence. Ceci donne :
Il s’agit de la même discussion que précédemment. On voit donc ici facilement l’arborescence. Lorsqu’un message est non lu, la branche à laquelle il est attaché est noire au lieu de grise ce qui permet de l’identifier du premier coup d’oeil. Les couleurs de fond des noeuds (une idée de Falco) sont obtenue à partir d’un hash quelconque sur l’émetteur et permettent donc d’identifier les messages envoyés par la même personne. Lorsqu’on laisse la souris sur un noeud, le nom de l’expéditeur et l’heure du post s’affichent (malheureusement le pointeur de la souris n’apparaît pas sur la capture d’écran)… et bien sûr quand on clique sur un noeud, on va sur le message correspondant.
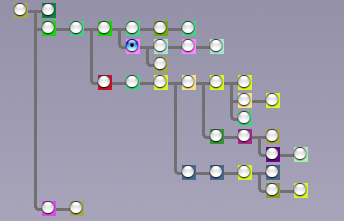
Lorsqu’on est sur un message, on garde également la vue du thread ce qui permet de toujours savoir où on est dans la discussion :
Il y a encore un peu de travail à faire pour améliorer les performances de la génération des arbres et pour augmenter sa compacité (éviter les branches qui descendent très bas alors qu’elles auraient pu trouver leur place dans le l’espace vide disponible).
]]><![CDATA[15 000]]>2007-10-08T00:32:00+02:00http://blog.mymind.fr/blog/2007/10/08/15-000Ca y est… 15 000 inscrits à Polytechnique.org.
Si l’ascension continue, nous devrions atteindre les 16 000 l’année prochaine.
]]><![CDATA[Compter Les Fichiers]]>2007-08-31T01:12:00+02:00http://blog.mymind.fr/blog/2007/08/31/compter-les-fichiersC’est un peu la suite de mon post “Outils pratiques” où je donnais deux scripts permettant de rendre les commandes SVN plus conviviales. Encore une fois, je réinvente sans doute la roue (des outils équivalents doivent déjà exister… sans doute en mieux), mais je pense que chercher ce genre d’outils sur internet m’aurait pris plus de temps que ce qu’il m’a fallu pour le développer.
En ce moment je manipule des fichiers, beaucoup de fichiers (et même, beaucoup de gros fichiers), que j’ouvre, rouvre, et ferme et puis referme. Et à force d’ouvrir, on oublie parfois de refermer, et là, c’est comme une fuite de mémoire, sauf que le nombre limite de fichiers ouverts est beaucoup plus rapidement atteinte que la limite de mémoire… dans la configuration de base sur un linux, un programme n’a le droit qu’à 1024 descripteurs de fichiers. D’où mon problème : comment traquer les “file-handle leaks” ?
Pour le faire, je me suis fait rapidement un petit script qui permet d’analyser les données issues d’un strace. strace est, pour ceux qui ne le savent pas, un programme très pratique qui permet de lister les appels systèmes. Dans mon cas présents, surveiller les ouvertures fermetures de fichiers revient à traquer les commandes open (ouverture d’un fichier), et les commandes close. Donc, je récupère simplement la liste des appels à open et close :
Et ainsi, le fichier /quelque/part contient la liste complète des appels à open et close effectués par mon programme (et ses processus fils). Il ne reste plus alors qu’à analyser le contenu de /quelque/part. Pour ceci, il suffit de peu de lignes de code (en perl pour ma part, mais d’autres auraient fait la même chose en shell, python… ou n’importe quel langage de scripting) :
#!/usr/bin/perl my%files;my%modes;my%lines;my$lineNb=0;my$maxOpened=0;my$currentOpened=0;my$totalOpened=0;for$line(<STDIN>){if($line=~ /open\\("([^""]+)", ([^\\)]+)\\)\\s*=\\s*(\\d+)/){$files{$3}=$1;$modes{$3}=$2;$lines{$3}=$lineNb;$totalOpened++;$currentOpened++;if($currentOpened>$maxOpened){$maxOpened=$currentOpened;}}if($line=~ /close\\((\\d+)\\)/&&$files{$1}ne''){$files{$1}='';$currentOpened--;}$lineNb++;}print"$totalOpened files opened, max. $maxOpened at the same time";print"$currentOpened files not closed";for$id(keys%files){local$file=$files{$id};local$mode=$modes{$id};local$line=$lines{$id};if($filene''){print"[line $line] id=$id, open $file with mode $mode";}}
Pour simplifier le tout, on rajoute une fonction dans le zshrc pour wrapper tout ça, et ça donne (attention, ceci ne fonctionne que sous linux, mktemp n’a pas la même syntaxe sur MacOS, et surtout, strace n’est pas disponible sur Mac
% gcc test.c -o tester
% checkFiles ./tester
3 files opened, max. 1 at the same time
1 files not closed
[line 4] id=3, open test with mode O_RDONLY
Voilà, maintenant je sais que mon programme oublie de fermer un fichier, que ce fichier s’appelle “test”, et qu’il est ouvert en read-only. La ligne “4” est la ligne dans la sortie de strace, et n’a aucun rapport avec la ligne 4 du fichier source (contrairement aux apparences).
]]><![CDATA[Templates en C]]>2007-08-17T00:53:00+02:00http://blog.mymind.fr/blog/2007/08/17/templates-en-cEn C++, il existe un mécanisme extrêmement pratique pour généré du code générique : les templates. Une fonction templatée est une fonction dont le code comporte un trou qui sera remplacé à la compilation par le nom d’un type, ou une valeur… Par exemple :
template <class T>
T read(const char *buffer)
{
T val;
memcpy(&val, buffer, sizeof(T));
return val;
}
Cette fonction lit un objet de type T sur un buffer. L’intérêt de cette fonction est très compréhensible : quel que soit le type qu’on fournit à la fonction, elle va fonctionner, en adaptant la taille à lire au type. C’est donc beaucoup plus rapide que d’écrire une fonction pour chaque type… et l’utilisation est également très simple :
read<int>(const char* buffer) // lit un entier sur le buffer
read<double>(const char* buffer) // lit un double sur le buffer
read<MaClass>(const char* buffer) // lit un objet de type "MaClass"
Mais cette syntaxe n’est qu’un sucre syntaxique, car en fait, on peut également faire des templates en C…
Comment fonctionne les templates ?
En fait un template est, comme son nom l’indique, qu’un modèle de fonction. Lors de la compilation d’un programme qui utilise des templates, le compilateur regarde la liste des instances de cette fonction qui sont utilisées et les génère. Plus explicitement, si j’appelle read(), le compilateur va générer cette fonction :
Ainsi, l’appel à read devient un appel de fonction classique.
Jeu de préprocesseur
Le préprocesseur en C possède des outils sympathique… Nous nous attarderons particulièrement sur le ##. Il s’agit tout simplement d’un opérateur de concaténation. Donc :
Maintenant, il ne reste plus qu’à générer les fonctions… sans avoir à toutes les écrire une à une. Pour ceci, nous allons encore une fois profiter de la présence du préprocesseur.
Il ne reste donc qu’à appeler maFonctionBuild(Type) sur chacun des types pour lesquels nous avons besoin d’instancier la fonction, et d’appeler maFonction(Type) chaque fois qu’on veut appeler maFonction pour le type en question. D’une certaine manière on peut dès lors dire que les fonctions sont :
TypemaFonction(Type)(constchar*buffer);
Et voilà !
Nous avons donc une implémentation générique grâce au préprocesseur associé à un appel typé. Ce n’est évidemment qu’une astuce de préprocesseur, mais cela donne une souplesse syntaxique agréalble : “J’appelle maFonction appliquée sur les entiers avec les arguments args”.
Tout ceci est certes, moins souple que les templates C++ :
il n’y a pas d’auto-instanciation par le compilateur : il faut “manuellement” instancier la fonction pour tous les types pour lesquels ont l’appelle
il n’y a pas de “type check” : les seules limites sont celle de la compilation
le correction des erreurs de compilation est fastidieuse car toutes les erreurs apparaissent comme étant à la ligne d’appel à maFonctionBuild
il est rapidement fastidieux de rajouter l’antislash à la fin de chaque ligne de la définition de la fonction
Comme on le voit dans les choix de l’exemple, pour les entrées/sorties, ça permet d’avoir une seule fonction à écrire tout en gardant la flexibilité d’une fonction par type de données.
]]><![CDATA[Comprendre Du Code]]>2007-08-15T03:28:00+02:00http://blog.mymind.fr/blog/2007/08/15/comprendre-du-codeJ’ai tenté cet après-midi une petite expérience sur IRC. J’ai posté 3 lignes de code en demandant “que font ces trois lignes”. Après quelques minutes (sans doute trop peu), j’ai donné la solution car personne n’avait vraiment trouvé. En effet, même si on réussi facilement à lire le code et à reconstituer la suite d’opération qu’il génère, il est très difficile de vraiment comprendre ce qu’il fait, d’imaginer son application dans un contexte et d’en déduire son usage.
Juste pour continuer à m’amuser, et pour amuser ceux qui se perdraient ici, voici le code en question.
do{++(*pos);}while(*(pos++)==0);
Vous pouvez remarquer dès à présent que ce code n’est pas volontairement rendu illisible (il serait facile de supprimer des parenthèses et de changer le test de nullité en une négation. Le but est donc de comprendre la suite d’instruction, de dire ce qu’elle fait et ensuite de comprendre dans quel contexte elle est utilisable. La question est aussi de savoir en combien de temps vous allez trouver la solution.
Fonctionnement
—————
Si on lit le code, on voit qu’il fait la suite d’opération suivante :
1 on incrémente la valeur pointée par pos
1 on regarde si la valeur obtenue est nulle
1 on incrémente le pointeur pos
1 si le test 2 est vrai, on retourne en 1, sinon, on quitte la boucle
Il s’agit donc d’une petite boucle qui incrémente des objets successifs jusqu’à ce qu’elle en trouve un qui, une fois incrémenté, n’est pas nul.
Voilà donc la solution du pauvre au problème, celle qu’on peut trouver en lisant le code, sans chercher à le comprendre.
Interprétation
—————-
Mais en fait, ce code va plus loin. Imaginons maintenant la zone mémoire sur laquelle pos pointe initialement :
oct1 oct2 oct3 oct4
^
pos
L’octet 1 à une certaine valeur. Je l’incrémente et je m’aperçois que sa nouvelle valeur est 0. Quand un octet incrémenté peut-il retomber à 0 ? Quand il fait un overflow. On a donc fait déborder le premier octet… et quand cet octet déborde on incrémente le suivant :
_+1__
| |
oct1 oct2 oct3 oct4
^
pos
Il s’agit donc ni plus ni moins que d’une retenue (comme quand on apprend à faire les additions ou les multiplications) : quand je fais déborder un octet, je déplace le surplus vers le suivant. Finalement, ces 3 lignes de code ne sont que l’implémentation d’une incrémentation, mais sur plusieurs octets… et même sur un nombre non défini d’octets (puisqu’il n’y a pas de limite explicitée sur le nombre d’étapes autorisées).
Pour être plus précis, il s’agit d’un incrémenteur d’entier stocké en Little Endian sur un nombre illimité d’octets.
Encore ?
———
Bon, pour ceux qui tiennent vraiment à s’assurer que ce n’est pas du code illisible, voici une version vraiment illisible de la même machine :
for(++*pos;!*pos++;++*pos);
(Merci Falco)
Tout ceci n’était bien sûr qu’un exemple. Il est toujours très dur de comprendre du code, alors pour éviter de passer dix minutes sur 3 lignes lors de la prochaine relecture il suffit de documenter ce qu’on écrit.
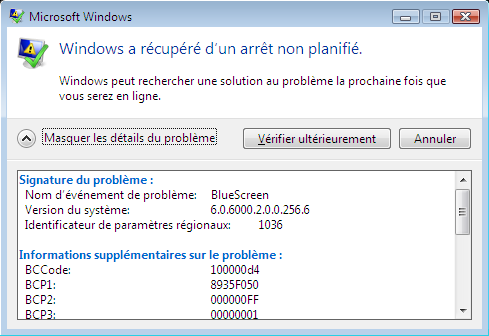
]]><![CDATA[BlueScreen]]>2007-07-28T23:15:00+02:00http://blog.mymind.fr/blog/2007/07/28/bluescreenJuste parce que je trouve ça amusant : lorsque Vista plante en raison d’une erreur sérieuse, il fait un écran bleu (exactement le même que sous Windows XP). Ce qui est amusant, c’est le message affiché lors du démarrage suivant de Windows.
Windows récupère donc d’une erreur de type “BlueScreen”… cela a l’intérêt d’être précis. En temps normal, on identifie une erreur à sa cause, et non à sa conséquence.
]]><![CDATA[Mail.app, IMAP Et Signatures...]]>2007-06-12T01:24:00+02:00http://blog.mymind.fr/blog/2007/06/12/mailapp-imap-et-signaturesLes temps sont durs pour les utilisateurs de IMAP… jusqu’à présent je n’ai pas trouvé de client idéal pour travailler avec ce protocole :
Kmail plante lamentablement
Mail.app se synchronise mal
Outlook Express (et le tout nouveau Windows Mail) n’arrive pas à lister tous mes répertoires
Thunderbird rame comme un malheureux et me crée des répertoires que je ne veux pas avant de m’avoir demandé quoi que ce soit
mutt est trop casse-pied à configurer à mon goût (même si pratique parfois)
De fait, j’utilise le moins pire que j’ai trouvé, et qui en plus a le mérite de ne pas être trop lourd, bien intégré avec MacOS X, et qui, jusqu’à présent, n’a pas trop fait de bêtises sur mon IMAP. Ce client, pourtant pas réputé pour sa qualité, c’est évidemment Mail.app.
Un gros défauts de Mail.app (une fois configuré pour éviter toutes les fonctions décoratives qui ne servent à rien), est qu’il ne gère pas nativement PGP. Il faut donc, pour profiter de la vérification des mails mais également pour signer ses mails, installer GPGMail, un petit plug-in qui fonctionne, on va dire, pas trop mal.
En tout cas, GPGMail a toujours fonctionné correctement sur mon portable, mais depuis que celui-ci est en réparation (hum, d’ailleurs, j’aimerais bien savoir ce qu’il devient !), je suis obligé de travailler sur le fixe, et donc d’utiliser entre autre mon client mail sur le fixe. Malheureusement, sur mon fixe, GPGMail n’a jamais réussi à vérifier une signature. Bizarre… les mêmes messages étaient pourtant correctement vérifiés par mon portable.
Comme, ça fait quelques temps que j’envisage d’ajouter le support de PGP (via GPG) à Banana, j’ai voulu regarder plus en détail comment fonctionne la signature d’un message. J’ai donc commencé à prendre des mails signés dans Mail.app, à en enregistrer les sources sur mon disque dur et à essayer de vérifier les signatures à la main, puis avec une version légèrement hackée de Banana. Malheureusement, ça n’a jamais fonctionner.
J’ai demandé à NC s’il pouvait me donner les sources d’un mail signé qui a le mérite d’apparaître comme correctement signé chez lui, et mal signé chez moi. J’ai comparé les 2 versions du mail… et le diff a été on ne peut plus troublant :
--nextPart1631992.9B81mC3O8N
-Content-Type: text/plain;- charset="iso-8859-1"
Content-Transfer-Encoding: quoted-printable
+Content-Type: text/plain;+ charset=iso-8859-1
Content-Disposition: inline
///
Le contenu de la partie signée n'est pas identique dans les deux mails. Pour ceux qui ne connaissent pas la structure d'un mail signé, je les invite à jeter un coup d'oeil à la [RFC1847|http://www.faqs.org/rfcs/rfc1847.html] qui se résume au schéma suivant :
La partie différente entre chez NC et chez moi est la partie @@stuff to sign@@ (en fait ce sont les en-têtes de la partie signée du message).
Donc, je me suis replongé dans les options de Mail.app : pourquoi modifie-t-il les sources de mon mail ? quelle est l'option qui est différente entre mon portable et mon fixe ? J'ai recherché dans les paramètres d'affichage et d'édition sans succès... et puis je me suis dit que j'allais regarder la configuration de mon compte IMAP.
Une différence majeure entre mon fixe et mon portable est que mon portable est susceptible de ne pas être constamment connecté au serveur IMAP, donc il est configuré pour conserver une copie de tous les mails alors que sur mon fixe, Mail.app est sur la même machine que le serveur IMAP, pourquoi irais-je faire une copie supplémentaire des mails (ce qui se concrétiserait par des accès disques concurrents et quelques centaines de méga-octets de données dupliquées) ?
Pourquoi ? et bien maintenant j'ai ma réponse... en demandant à Mail.app de garder une copie des mails, GPGMail arrive à vérifier les signatures, donc, dans ces conditions, il a accès aux sources non modifiées. Il y a donc quelque part dans Mail.app un outil qui transforme les sources des mails... assez hallucinant ! Il faut donc que je considère que si je demande à Mail.app de m'afficher les sources d'un message qui se trouve sur un serveur IMAP sans faire de copie locale, il est possible (probable ?) que les sources en question ne soient pas les vraies sources du message mais une version ''remasterisée'' par Apple.
Même si je ne me fais pas trop d'illusion sur le sujet, j'espère que ce genre de détails (tout comme également la gestion des URLs dans le @@format=flowed@@, ou encore l'affichage de l'arborescence des message...) sera corrigé dans Leopard.
]]><![CDATA[Khtml2png 2.6.5 Est Sorti]]>2007-06-06T00:31:00+02:00http://blog.mymind.fr/blog/2007/06/06/khtml2png-265-est-sortiAprès 3 mois d’un travail pas très intensif, une nouvelle version de khtml2png est disponible. Cette version est partie du fait que les versions précédentes du programme ont parfois du mal à gérer les grandes captures d’écran (en fait, des bugs peuvent apparaître dès que la taille de la zone à capturer est plus grande que la taille affichable).
Donc, rapidement après la sortie de la 2.6.0, j’avais envoyé un correctif (en fait une réécriture du moteur de rendu) au développeur de khtml2png. Malheureusement, ce correctif ne fonctionnait pas correctement chez lui. Donc, pendant 3 mois, j’ai fait du débuggage à distance : j’envoie une version modifiée (1 ou 2 lignes à chaque fois), j’attends 2 ou 3 semaine une réponse, etc… Du développement efficace !
Bon, toujours est-il que maintenant, la version 2.6.5 fonctionne à la fois chez moi (à la fois Debian + xvnc et sur MacOS X), et chez Hauke (sur Debian également, mais avec des réglages différents).
Le Changelog annonce :
fix: Now produces screenshots on my Debian Etch system under KDE 3.5.5 without glitches. %%%
fix: Maybe better working on other systems too. Please test.
J’aimerais y rajouter quelques points :
meilleur moteur de rendu (qui ne scroll plus, mais déplace la fenêtre pour s’affranchir de certains bugs de KDE et/ou Qt)
meilleure détection de la taille de la capture à réaliser
possibilité de choisir le comportement de khtml2png face aux redirections, au javascript, au java, au flash… via la ligne de commande
la détection automatique de la dimension par un id devient compatible avec le format utilisé dans les version <= 2.5
]]><![CDATA[Spaces]]>2007-06-02T16:44:00+02:00http://blog.mymind.fr/blog/2007/06/02/spacesComme un certain nombre de personnes le sait déjà, j’ai repris le développement de VirtueDesktops depuis quelques semaines. Dans un premier temps je n’avais pas regardé le fonctionnement bas niveau du programme, mais la semaine dernière j’ai commencé à rechercher dans les sources “Comment Virtue fait-il pour cacher les fenêtres, faire les transitions etc… ?”.
A ma grande surprise, tout ceci est en fait géré nativement par MacOS X… la bibliothèque CoreGraphics contient en effet quelques fonctions cachées qui gèrent l’attribution d’une fenêtre à un Workspace et les transitions entre ces Workspaces. On peut trouver la liste complète de ces fonctions sur la SVN de VirtueDesktops.
VirtueDesktops (et également DesktopsManager) n’est qu’une interface graphique qui tente d’utiliser ces fonctions. Et là Spaces part avec une longueur d’avance car contrairement à VirtueDesktops, il sera facile pour Apple de gérer les ouvertures, fermetures et masquage d’application ce qui est à mon avis le plus gros point faible de Virtue. J’ai beaucoup travaillé là-dessus et je pense arriver actuellement aux limites de ce qu’il est possible de faire avec un gestionnaire de bureaux virtuels sur Tiger.
Un autre problème de VirtueDesktops est l’accès à l’ordonnancement des fenêtres. Comment être sûr que lorsqu’on arrive sur un bureau les fenêtres sont dans le bon ordre ? Idéalement il faudrait enregistrer l’ordre en temps réel et le restaurer lors du retour sur le bureau. Ceci permettrait également de toujours savoir quelle application activer lorsqu’on arrive sur un bureau, simplement en utilisant la fenêtre qui se trouve au premier plan.
Voilà, je me suis certes lancé dans une cause perdue d’avance, mais je suis tout de même content du résultat obtenu lors de ces dernières semaines. Virtue a désormais un comportement qui correspond à ce que j’attends d’un gestionnaire de bureaux virtuels : quand je change d’application il va sur le bureau adéquat, et quand je change de bureau, il active bien la dernière application que j’ai utilisée sur ce bureau.
]]><![CDATA[Et Si on Oubliait Les Bases ?]]>2007-05-26T13:40:00+02:00http://blog.mymind.fr/blog/2007/05/26/et-si-on-oubliait-les-basesMacOS X est un Unix… compatible POSIX. Voilà ce qu’un certain nombre de personnes semblent oublier assez fréquemment. C’est assez dommage quand ces personnes programment pour MacOS, on se retrouve parfois avec du code complexe pour réécrire des fonctions POSIX (en moins bien ?).
En fait si je parle de ça, c’est parce que je viens de rencontrer le problème dans le cadre du développement de VirtueDesktops. Il se trouve qu’en parcourant le tracker du projet je suis tombé sur le ticket 115 qui s’intitule :
Patch to check group id of ‘procmod’ group
C’est intéressant… jusqu’à maintenant Virtue suppose que le gid du groupe procmod est celui par défaut de MacOS (c’est à dire qu’il vaut 9)… et le problème est donc que si un utilisateur a un procmod différent (ou si Apple décide un jour de changer le gid du groupe), le code actuel peut avoir des résultats inattendus, il faut donc faire un code plus portable qui recherche le gid de procmod au lieu de le stocker en dur. Ce n’est clairement pas une mauvaise idée ! Seul problème, le patch soumis est le suivant (au cas où certain voudrait réutiliser ce code, je tiens à signaler que c’est une mauvaise idée !) :
#define NI_DOMAIN "."#define NI_PATH "/name=groups/name=procmod"#define NI_KEY "gid"// Sucked from netinfo-369.5/tools/niutil/niutil.cni_statusni_read_single_prop(char**property){constchar*args[]={NI_DOMAIN,NI_PATH,NI_KEY};charmyname[]="ni_read_single_prop";constboolopt_tag=false;constinttimeout=30;ni_namelistnl;void*domain;ni_iddir;ni_statusret;if((ret=do_open(myname,args[0],&domain,opt_tag,timeout,NULL,NULL))!=0)returnret;/* args[1] should be a directory specification */ret=ni2_pathsearch(domain,&dir,args[1]);if(ret!=NI_OK){fprintf(stderr,"%s: can't open directory %s: %s", myname, args[1], ni_error(ret));ni_free(domain);returnret;}/* get the property values for args[2] */NI_INIT(&nl);ret=ni_lookupprop(domain,&dir,args[2],&nl);if(ret!=NI_OK){fprintf(stderr,"%s: can't get property %s in directory %s: %s", myname, args[2], args[1], ni_error(ret));ni_free(domain);returnret;}if(nl.ni_namelist_len!=1){fprintf(stderr,"%s: expected length = 1, found length = %d", myname, nl.ni_namelist_len);returnNI_FAILED;}*property=(char*)calloc(strlen(nl.ni_namelist_val[0])+1,sizeof(char));strcpy(*property,nl.ni_namelist_val[0]);ni_namelist_free(&nl);ni_free(domain);returnNI_OK;}
Donc que fait cette fonction ? C’est assez simple : elle utilise l’utilitaire NetInfo d’Apple pour lire les informations relatives au chemin /groups/procmod. Une fois là dedans elle copie la valeur stockée à la clé gid et renvoie cette chaîne dans le pointeur passé en argument.
Il n’y a pas à dire… c’est une solution qui devrait fonctionner (enfin j’ai même un doute, car je ne vois pas le groupe procmod apparaître quand je regarde dans NetInfo). Seulement cette solution montre clairement que la personne qui l’a écrite savait que MacOS utilise un système de groupes, mais avait oublié qu’en fait c’est avant tout un système POSIX. Et là, ce qui est intéressant c’est que sous MacOS X on a accès à l’API POSIX… en particulier à la fonction getgrnam qui retourne les informations sur un groupe à partir de son nom.
Donc, pas besoin de dépendance vers NetInfo, pas besoin d’une recherche dans une arborescence abstraite : NetInfo n’est qu’une abstraction de la couche Unix pour simplifier l’accès aux données par les utilisateurs… mais ça ne doit pas être un framework d’abstraction de l’API POSIX ce qui entraîne nécessairement du code moins portable (et surtout, moins lisible dans le cas présent), moins rapide et plus lourd.
Ici, le code est utilisé dans un programme en C qui est chargé de mettre un objet dans le groupe procmod pour autoriser Virtue à effectuer certaines actions qui nécessitent un accès privilégié au serveur graphique… ce programme ne fait que changer les permissions. Pourquoi utiliser une API lourde et spécifique à MacOS alors que ce type de programme pourrait clairement être utilisé sur n’importe quel Unix ?
Voici donc une solution qui fait la même chose que la fonction ci-dessus, en mieux et surtout en beaucoup moins de lignes :
elle retourne un entier… on a donc pas besoin de faire une conversion a posteriori
elle utilise l’API POSIX et est donc utilisable sur n’importe quel OS POSIX (donc quasiment tous… à l’exception de Windows)
elle évite toute manipulation inutile de chaîne de caractères
elle est ne nécessite pas de charger une bibliothèque supplémentaire : getgrnam est dans la libc
elle est drôlement plus courte non ?
]]><![CDATA[Mac C'est Bien... Mais Pas Top]]>2007-05-22T23:44:00+02:00http://blog.mymind.fr/blog/2007/05/22/mac-cest-bien-mais-pas-topBon, la suite des mes problèmes avec les machines Apple !
Alors que la carte mère de mon portable a été changée il y a un peu plus d’un mois, mon portable a décidé aujourd’hui d’arrêter de vouloir fonctionner. Symptômes ? Il s’allume (des fois), fonctionne (rarement) quelques secondes puis s’éteint brutalement… et ce qu’il démarre sur secteur, sur batterie ou les deux ensemble, que ce soit sur le disque dur, sur le DVD d’installation ou encore en mode target (en tant que disque dur externe).
En plus ça lui arrive de s’allumer tout seul alors que ça fait plusieurs minutes que je ne l’ai plus touché. Un autre symptôme étrange, la diode de la prise magsafe clignote bizarrement lorsque la machine n’est pas sous-tension (pas un clignotement vert/rouge, mais une lumière verte continue qui scintille un peu). Tout ça me laisse penser que c’est l’alimentation qui est en cause.
Voilà… les joies des machines de qualité, d’autant plus que la garantie de la machine a expirée il y a 2 jours (le 19 mai).
]]><![CDATA[VirtueDesktops Revient...]]>2007-05-18T14:25:00+02:00http://blog.mymind.fr/blog/2007/05/18/virtuedesktops-revientVoici plus ou moins trois mois que j’ai découvert synergy, c’est vraiment très agréable de pouvoir contrôler les deux ordinateurs sans changer de clavier/souris continuellement. Seul problème, c’est que sur la machine qui héberge le serveur synergy, VirtueDesktops, un excellent gestionnaire de bureaux virtuels pour MacOS, n’arrête pas de crasher. J’avais donc posté un bugreport sur le trac de Virtue… malheureusement pour diverses raisons, Tony Arnold a décidé peu après de stopper le développement de Virtue.
J’ai donc pris mon courage à 2 mains, et je me suis doucement plongé dans le code de VirtueDesktops (c’est vraiment bien les applications OpenSource). Il y a maintenant deux semaines, j’ai soumis le patch permettant de corriger le crash dont je souffrais. Depuis, ce patch a été publié ce qui a conduit la release de la bêta 3 de Virtue 0.54.
Je me suis relancé dans le développement cette semaine en me fixant comme objectif de corriger plusieurs comportements énervants de Virtue. Par exemple, si je dis que Mail.app doit être sur le bureau Mail, je veux que toutes les fenêtres de Mail.app aillent forcément sur ce bureau. Seul problème, c’est que lorsque je reçois une notification de l’arrivée d’un nouveau mail et que je clique sur cette notification, une fenêtre avec le message s’ouvre sur le bureau courant, et Virtue tourne pour atteindre le bureau de Mail.app… résultat : j’ai changé de bureau mais je n’ai pas accès à la fenêtre que je voulais voir. J’ai corrigé ce comportement, désormais, la fenêtre est automatiquement déplacée sur le bureau de Mail.app lors de son ouverture.
Autres corrections diverses :
lorsqu’on ferme une application Virtue reste sur le bureau courant (sauf si il n’y a plus rien sur le bureau courant)
lorsqu’on choisi de changer de bureau, Virtue active désormais la dernière application active connue pour le nouveau bureau
lorsqu’on restaure une fenêtre qui était dans le Dock, soit l’application a le droit d’être sur le bureau courant et la fenêtre est affichée sur ce bureau sans chercher à changer de bureau, soit l’application est attribuée à un bureau et dans ce cas la fenêtre est restaurée sur le bureau de l’application et Virtue change de bureau
…
Ces changements ont abouti à la bêta 4 et se résument à :
Changing to desktops when you launch, activate, deactivate, minimise, restore or quit an application should be much more consistent;
Window ordering when changing desktops should be much more consistent;
]]><![CDATA[La Banane Et L'escargot]]>2007-05-07T19:44:00+02:00http://blog.mymind.fr/blog/2007/05/07/la-banane-et-lescargotLa release de Banana 1.6 en même temps que celle de plat/al 0.9.14 a mis en évidence un certain nombre de faiblesses dans Banana. En particuliers la génération du spool (mise en cache de l’arborescence des messages) et des flux RSS s’est révélé extrêmement lourde pour plusieurs raisons :
l’accès aux mbox des Mailing-Lists nécessite d’appel du mbox-helper, et donc un fork… opération lourde, qui répétée plusieurs fois par mbox devient rapidement très lourde lorsqu’on a plusieurs dizaines de Mailing-Lists.
le traitement des données par PHP est loin d’être immédiats… et il y a clairement des goulots d’étranglement dans le code.
C’est pour ces raisons que j’ai passé Banana au profiler, c’est à dire que j’ai analysé l’exécution de Banana à l’aide d’un outil qui permet de tracer l’exécution du programme et mettant un accent particuliers sur le temps d’exécution de chaque fonction. L’outil que j’ai trouvé pour faire ça est xdebug, utilisé conjointement à KCacheGrind.
Forks
Je dois avouer que lorsque j’avais fait mes tests, je n’avais pas plusieurs centaines de Mailing-Lists à traiter… et je ne m’attendais pas à ce qu’une fois passée en production le script de mise à jour des flux RSS puisse prendre toutes les ressources de la machine pendant plusieurs minutes. Il a donc fallu sérieusement restructurer la gestion des accès aux Mailing-Lists pour restreindre au maximum le nombre d’accès au mbox-helper (un petit programme écrit en C qui se charge de tous les accès aux mbox), et, en cas d’accès, limiter au maximum le temps passer sur le mbox-helper.
Donc désormais le mbox-helper n’est plus appelé que si la mbox a changé depuis le dernier passage (le changement étant détecté par la taille du fichier). Ce qui permet donc de supprimer le lancement d’environ 500 mbox-helper lors des rafraîchissements des spools (en effet, un nombre négligeable de Mailing-List aura des nouveaux messages lors du passage du script toutes les 5, 10 ou 20 minutes). Ajouté à cela la correction d’un bug qui faisait que l’appel au mbox-helper oubliait de spécifier l’offset où chercher le message à traiter et qui forçait donc le mbox-helper à relire la totalité de la mbox, on peut se permettre de supposer que la prochaine version de Banana sera plus efficace pour la gestion des mbox.
Array_shift
Piles
Il est souvent extrêment pratique d’utiliser une pile de données. Cela permet de traiter les informations dans l’ordre de la pile sans excès de mémoire puisque chaque élément est dépilé avant d’être traité. C’est une technique que j’aime particulièrement lorsque j’ai une suite de lignes à traiter : je prend un tableau contenant une ligne par entrée et je le parcours avec array_shift qui permet de dépiler le premier élément du tableau. On obtient ainsi un code de la forme
while (!is_null($line = array_shift($lines))) { do_something($line);}do_something($lines);
Un foreach peut très bien faire la même chose, mais on perd les avantages de la piles. Avec cette structure, pour avoir le même comportement que la boucle précédente, il faut ajouter un unset() :
foreach ($lines as $key=>&$value) { do_something($line); unset($lines[$key]);}do_something($lines);
Certes le foreach sera sensiblement plus rapide que le while/array_shift() car il comprend un appel de fonction à chaque itération, mais on peut s’attendre raisonnablement à ce que cet appel soit en O(1), et ait donc un coût négligeable.
Profiler
Là où il y a un problème c’est que le profiler m’indique que array_shift prend 57% du temps d’exécution de Banana. Ces 57% sont partagés entre 80000 appels à la fonction, mais le plus marquant c’est que parmi ces 80000 appels, ce ne sont que 24000 d’entre eux qui prennent la quasi-totalité du temps. Pourquoi ces appels particuliers sont-ils si lourd alors que les 60000 autres ont un coût parfaitement négligeable.
La seule différence entre ces deux cas d’appels c’est que les lourds traitent un énorme tableau de 24000 lignes, alors que les légers traitent un grand nombre de petits tableaux de quelques dizaines de lignes chacun. Il est donc extrêmement clair que array_shiftn’est pas une fonction en O(1)… J’ai donc changé la structure de code qui reflétait la structure de données par une simple boucle qui perd en lisibilité dans ce patch. Après ce changement, les 60000 array_shift restant ne prennent que 0.16% du temps d’exécution de Banana…
]]><![CDATA[Vista ?]]>2007-05-03T18:07:00+02:00http://blog.mymind.fr/blog/2007/05/03/vistaÉtant curieux, en tout cas pour ce qui est informatique, je n’ai pas pu m’empêcher de mettre un Windows Vista en double boot sur mon MacBook Pro… Grâce à BootCamp, l’installation ne pose pas de problème. Par contre une fois l’OS installé, je n’ai pas arrêtez d’enchaîner les petits problèmes qui ont été plus une perte de temps qu’autre chose…
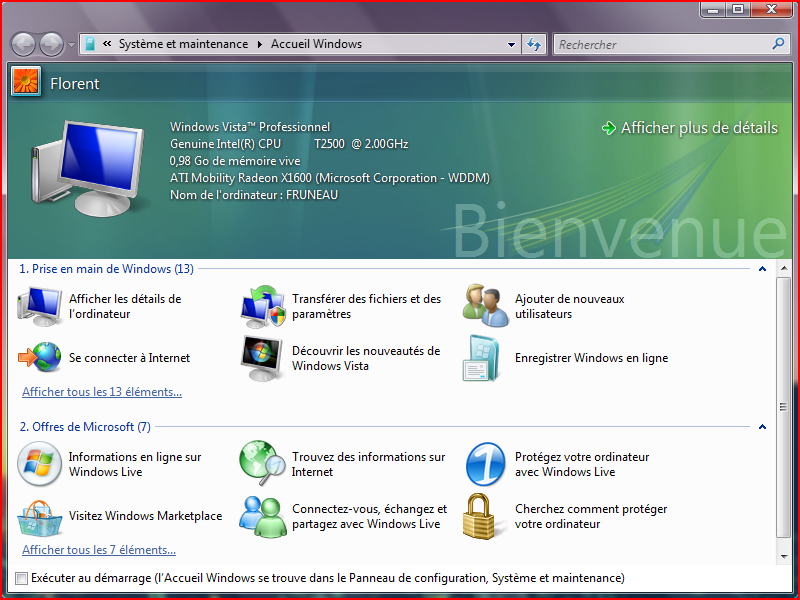
Accueil réussi
Les problèmes commencent dès l’arrivée sous Vista. Déjà un premier coup d’oeil : c’est loin d’être laid à regarder… même si les ombres sont moins agréables que celles de MacOS X et que les effets de flouté sous les fenêtres me fatiguent un peu. Quand on arrive sous Vista, on tombe sur la fenêtre Accueil de Windows ci-dessous :
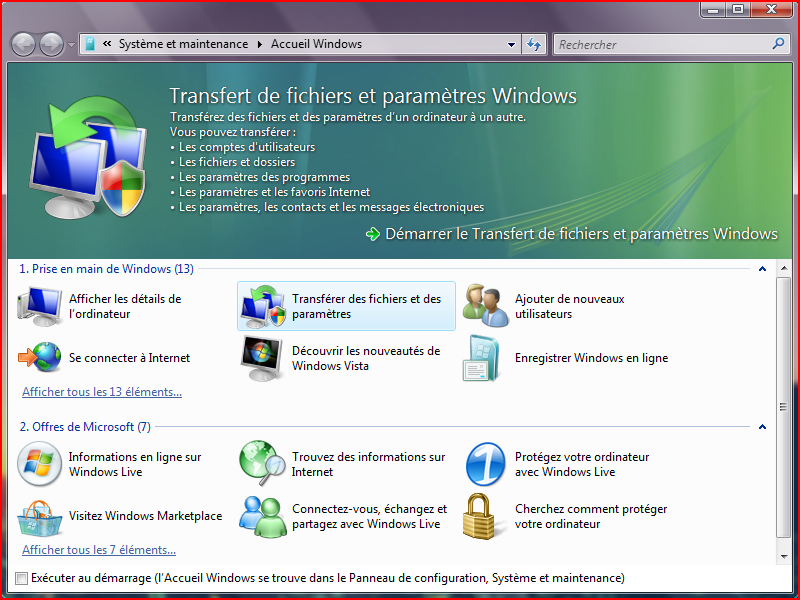
Cet écran est sympathique : un navigateur pratique pour circuler entre les fonctionnalités de Windows… le problème provient lorsque justement je clique sur une de ces fonctionnalités, par exemple “Transfert de fichiers”… rien ne se passe. Enfin, je m’attendais à voir surgir un assistant, mais rien n’apparaît. Après quelques secondes, je me rends compte qu’en fait l’en-tête de la fenêtre à changé :
Il faut cliquer sur le texte en bas de l’en-tête pour enfin avoir le logiciel de Transfert de fichier… qui se lance dans un environnement bizarre en plein écran avec une petite fenêtre au milieu.
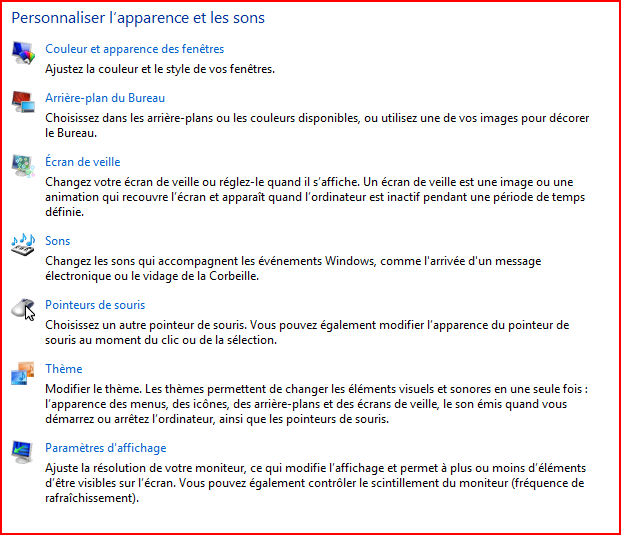
Personnalisation
Le premier réflexe après avoir installé un nouveau système, c’est de le personnaliser. Ceci passe donc par le changement du fond d’écran, de l’écran de veille, etc… Sous Vista, ceci se fait via une page du panneau de configuration :
C’est très bien, ça marche… sauf que lorsqu’on arrive à la catégorie Thèmes, changer le thème change tous les réglages qu’on avait faits précédemment pour les remplacer par ceux du thème sélectionné… L’art et la manière de perdre 10 minutes à faire 2 fois la même configuration, et à refaire tout ce que j’avais déjà fait alors que si Thèmes se trouvait en première place de cette liste, j’aurais d’abord choisi un thème avant de le personnaliser.
Inquiétude
Un autre problème se manifeste sous Windows Vista : les ventilateurs de mon MacBook Pro tournent quasiment à fond… alors qu’en temps normal c’est une machine silencieuse, sous Vista mon portable génère un fond sonore désagréable. Comme après avoir cherché un peu, je trouve qu’il y a un gadget (ce n’est pas du tout la même chose que les widgets de Dashboard) pour le panneau latéral de Windows qui permet de (plus ou moins) monitorer la charge CPU et l’occupation mémoire, je l’active. Et là, quelle bonne surprise ! Vista tourne à 15% proc comme occupation de croisière (étant donné que j’ai un dual-core, dois-je considérer que c’est 30% d’un des coeurs ?)… Quand je bouge la souris (si si, ça fait varier la charge), une fenêtre, ou que je travail sur une application, la charge proc augmente. Par exemple, les deux captures suivantes montre la charge de la machine lorsque j’utilise le logiciel de capture d’écran :
la première lorsque je capture par sélection (une fois la sélection terminée, il est monté aussi à 30% CPU pendant quelques secondes)
la deuxième lorsque je capture par fenêtre (dans ce cas, il prend du processeur pour faire de joli effets graphiques pour mettre en valeur la fenêtre sélectionnée)
C’est donc mon processeur qui gère les effets graphiques ??? Pourtant j’ai une bonne carte graphique (ATI X1600) et d’après les benchmarks effectués par Vista, j’ai même une bonne machine, bien adaptée à Vista… je n’ose pas imaginer ce que ça donnerait sur une machine un peu moins puissante.
Mais encore…
J’ai également passé beaucoup de temps à chercher comment diminuer l’espace disque occupé par Windows : je n’ai alloué que 20Go à la partition pour Windows, et j’aimerais bien pouvoir y installer 2 ou 3 jeux quand même… donc limité la taille de la mémoire virtuelle, la taille de la corbeille… par contre j’ai mis plus d’une demi-heure à trouver comment désactiver la restauration système. Et j’ai eu de la chance de finir par trouver en décochant au hasard une case dans une fenêtre de configuration sur laquelle j’ai abouti sans trop savoir comment !
Je ne m’étendrais pas sur tous mes déboires avec le nouveau menu démarrer de windows et le nouveau navigateur de programmes grâce auquel je n’ai toujours pas réussi à lancer une application du premier coup (à chaque fois je clique sur celle juste au-dessus), ni sur la gestion des droits d’accès qui n’arrêtent pas de me demander dans une jolie fenêtre sur un écran grisé si je veux continuer sans me demander de taper le moindre mot de passe (bah oui, mon compte ayant les droits d’administrateurs, je suppose que ça ne sert à rien de me demander un mot de passe), ni sur le temps et le nombre de clics nécessaires pour supprimer un fichier, ni sur Windows Mail qui ne trouve que 48 des 140 répertoires de mon serveur IMAP, ni même sur le pseudo-Exposé de Windows qui affiche les fenêtres les unes sur les autres et qui me force donc à scroller pour trouver celle que je veux alors qu’il serait tellement plus efficace de les mettre côte à côte (comme avec Exposé :).
Donc, Vista c’est beau, mais c’est tout… Je trouve l’ergonomie du nouveau système de microsoft déplorable. Je suis bien content avec mon MacOS X qui utilise la carte graphique pour les effets graphiques, qui ne fait pas trop de fioritures et qui me permet de trouver rapidement ce que je cherche sans avoir à parcourir 50 menus.
]]><![CDATA[0.9.14 en Ligne !]]>2007-04-29T21:09:00+02:00http://blog.mymind.fr/blog/2007/04/29/0914-en-ligneCa y est, comme annoncé dans mon billet de fin mars, la version 0.9.14 de plat/al est en ligne depuis vendredi soir. Comme expliqué précédemment, cette version apporte un grand nombre d’innovations comme le flux RSS pour les Mailing-Lists et les Fora, la recherche par proximité sonore améliorée et généralisée, un système d’annonces retravaillé pour offrir un approche plus conviviale, et bien sûr, le passage en UTF-8.
Mais de tout cela, j’en ai déjà parlé… je tiens par contre à m’étendre sur les quelques fonctionnalités qui ont été développées durant le dernier mois (en fait, durant les dernières deux semaines de développement, le reste du temps ayant été consacré aux tests).
Recherche interactive
Caribou a réalisé un énorme travail sur la mise en place d’un remplissage automatique (auto-completion pour les geeks) sur la recherche avancée. Ainsi, lorsqu’on tape quelques caractères dans un champ, une liste de propositions apparaît avec pour chaque proposition le nombre de camarades correspondant à la requête. Ce qui donne par exemple :
Par contre, là où cela devient très intéressant, c’est que l’interface reste flexible : si vous préférez choisir dans une liste des valeurs possibles plutôt que d’utiliser l’auto-completion, ce qui est envisageable, il suffit, si c’est disponible pour le champ correspondant, de cliquer sur la petite icône représentant une liste en fin de ligne… Ainsi, pour les pays, cela donne :
Il s’agit du même champ dont le a été remplacé par une
Sondages
Les sondages étaient la seule fonctionnalité du site qui avait été perdue lors du passage à plat/al il y a maintenant 2 ans et demi. C’est maintenant réparé grâce au travail de pika. Cette fonctionnalité étant de fait encore jeune, on peut s’attendre à ce que l’interface soit retravaillée fortement dans les prochaines versions du site pour s’adapter aux attentes des utilisateurs. Néanmoins, il est à noter que l’édition des sondages a été travaillée de telle sorte qu’un sondage soit facilement éditable : l’utilisateur qui crée un sondage peut aisément ajouter, supprimer ou modifier des questions, et les administrateurs ont accès exactement aux mêmes fonctionnalités pour la maintenance des sondages.
Nous attendons maintenant l’utilisation de cette fonctionnalité pour avoir des retours de la part de nos utilisateurs. Si l’expérience se révèle concluante, les sondages seront intégrés à Polytechnique.net pour que les animateurs les aient à leur disposition directement depuis l’interface de gestion des groupes.
Ensemble d’utilisateurs
Il s’agit de la partie sur laquelle j’ai travaillé, et donc celle que je connais le mieux, mais c’est aussi la partie la plus abstraite. Pour l’utilisateur, ça ne change quasiment rien, par contre au niveau du moteur du site, c’est à mon sens un pas en avant important vers des interfaces plus adaptées aux besoins des utilisateurs. C’est pour cette raison que cette partie risque d’être un poil technique.
Ce dont je parlais au paragraphe précédent est la gestion des ensembles d’utilisateurs… mais qu’est-ce donc ? un ensemble d’utilisateur est tout simplement une sélection d’utilisateurs dans l’annuaire, ça peut être les membres d’une Mailing-List, les contacts d’un utilisateur, les membres d’un groupe, les camarades correspondant à une recherche…
Le problème est que je voudrais que dès que sélectionne un ensemble d’utilisateur, je puisse séparer totalement la représentation de ces utilisateurs de la sélection qui est faite : ainsi si je choisi mes contacts, je veux pouvoir afficher mes contacts sur un planisphère, voir le trombinoscope de mes contacts, mais aussi voir leurs fiches… mais je voudrais avoir les mêmes outils pour toute autre sélection d’utilisateur.
La résolution propre de ce problème (c’est-à-dire, sans tout recoder à chaque cas possible d’utilisation) est l’utilisation d’un outil orienté Model/View :
le modèle gère la parti sélection des utilisateurs en fonction de la page
l’afficheur sélectionne les données à afficher pour les utilisateurs et génère ce que l’utilisateur verra
Dans plat/al, le Model s’appelle PlSet (duquel hérite un UserSet spécialisé dans les ensembles d’utilisateurs), et le View s’appelle PlView. De cette manière, l’affichage des contacts se fait en 5 lignes de code :
On crée le UserSet en lui donnant les critères de sélection des utilisateurs à afficher, puis on ajoute les Views à utiliser, enfin on gère l’affichage (en fonction des arguments passés à l’affichage de la page). C’est le type d’abstraction qui font vraiment plaisir car finalement on se rapproche du slogan de Qt : .
Bien sûr, il faut développer tout le background, mais le temps de développement est négligeable comparé à celui qu’on aurait passé à dupliquer ce code, voire justement à ne pas le dupliquer en raison de la complexité de certains cas. Un autre exemple d’utilisation est sur l’annuaire des groupes sur Polytechnique.net :
Dans ce cas, comme UserSet sait que s’il est appelé dans le cadre d’un groupe-X sur Polytechnique.net, il ne doit pas sélectionner d’utilisateurs hors de l’annuaire de ce groupe, il n’y a aucune restriction à lui indiquer : tout l’annuaire du groupe est sélectionné. On ajoute les deux modules de représentation qu’on désire utiliser : trombinoscope et Planispère, et applique à la page… en 4 lignes c’est fait.
Je m’extasie devant ce travail parce que je suis content du résultat, mais il n’est pas pour autant parfait. Son problème actuel est dû au background basé sur SQL : chaque élément (PlSet ou PlView) apporte des bribes d’une requête SQL permettant de finalement obtenir toutes les informations à afficher (PlView) pour les utilisateurs sélectionnés (PlSet), mais il peut arriver qu’une même donnée soit utilisée pour la sélection et pour l’affichage. Dans ce cas, la solution la plus simple est de dupliquer les jointures dans la requête, mais c’est une solution qui peut sérieusement alourdir et ralentir la requête.
L’implémentation actuelle gère la duplication au cas par cas : les PlView peuvent contenir tester s’il faut sélectionner un champ ou non en testant la classe du PlSet utilisé. Cette solution n’est pas particulièrement propre. La meilleure solution envisageable est d’utiliser une abstraction des champs SQL : chaque élément ne donnerait plus une bribe de requête SQL mais des informations sur “comment sélectionner la donnée”… ensuite la génération de la requête consiste à comparer toutes ces informations et à les assembler. Plat/al possède déjà les outils nécessaires pour réaliser ce jeu d’assemblage… ce sera très probablement pour la prochaine release.





{kind=link}